Improving LLM Applications
Improve your LLM outputs by collecting structured feedback and fine-tuning examples using the Improvement Datasets Features.
Overview
Improving LLM Apps allow users to create custom datasets to store examples of prompts, user queries, contexts, and model outputs. These datasets can then be used to retrain models based by allowing users to customize these datasets.
How It Works
1. Create an Improvement Dataset
Start by creating a new improvement dataset
Each dataset includes:
name: A descriptive name for the dataset (e.g., "Incorrect Summaries" or "Customer Support Errors").description: Optional longer explanation of the dataset’s purpose.
Steps to create the dataset
- Go to the Datasets section in the application sidebar.
- Click on the Improvement Datasets tab.
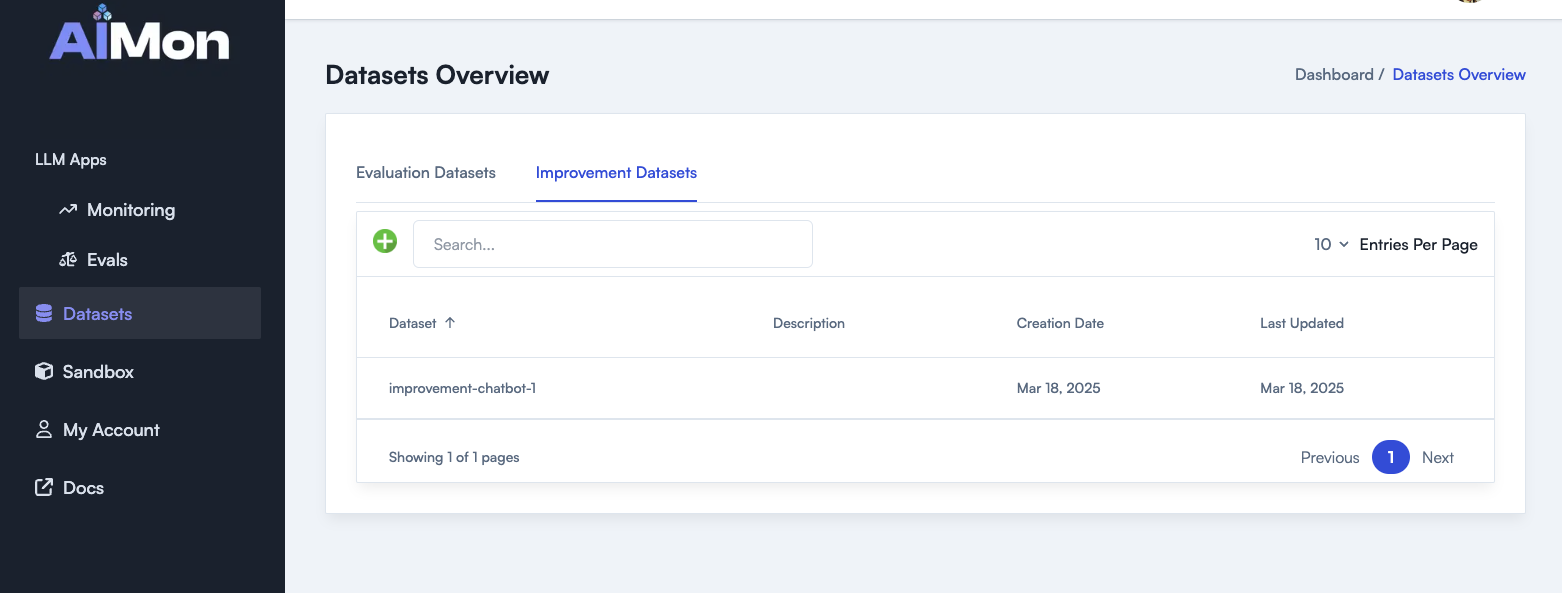
- Click the Create (Green
+button) button to open the creation modal. - Fill in the dataset name and (optionally) a description.
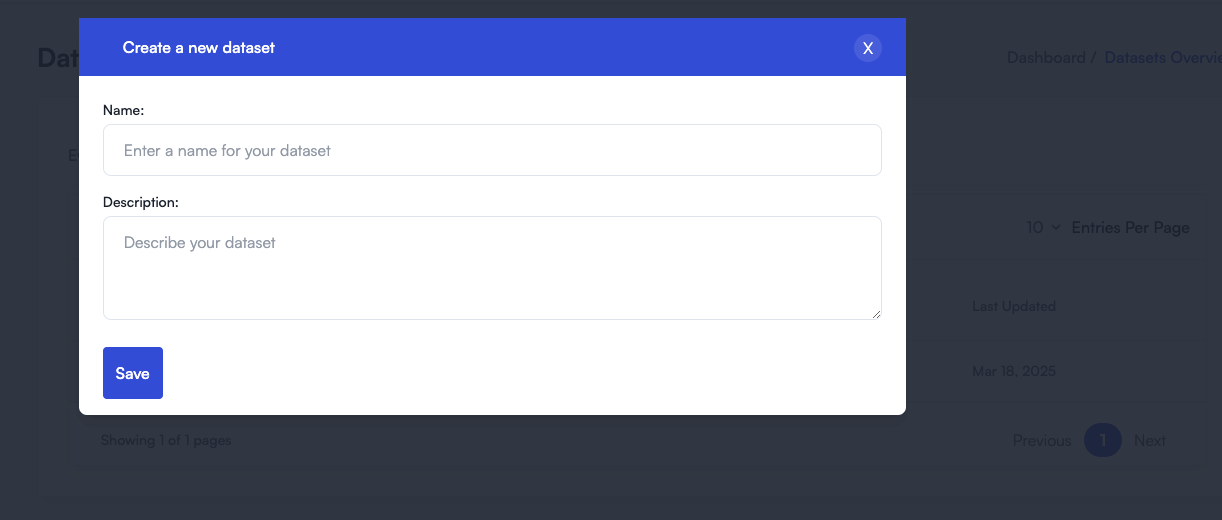
- Click Save to create your dataset.
Once the dataset is created, it will appear in the list and can be populated with records.
2. Add Records to the Dataset
Once the dataset is created, you can populate it with new records. Each record represents a specific prompt and response that can be used to evaluate or improve model behavior.
Each record contains:
user_query: The original user inputcontext_docs: The context passed to the model (e.g. retrieved documents)instructions: Any task-specific instructionprompt: (Optional) The full prompt that was sent to the LLM to generate anoutputoutput: (Optional) The LLM's output
Steps to add a record to the dataset
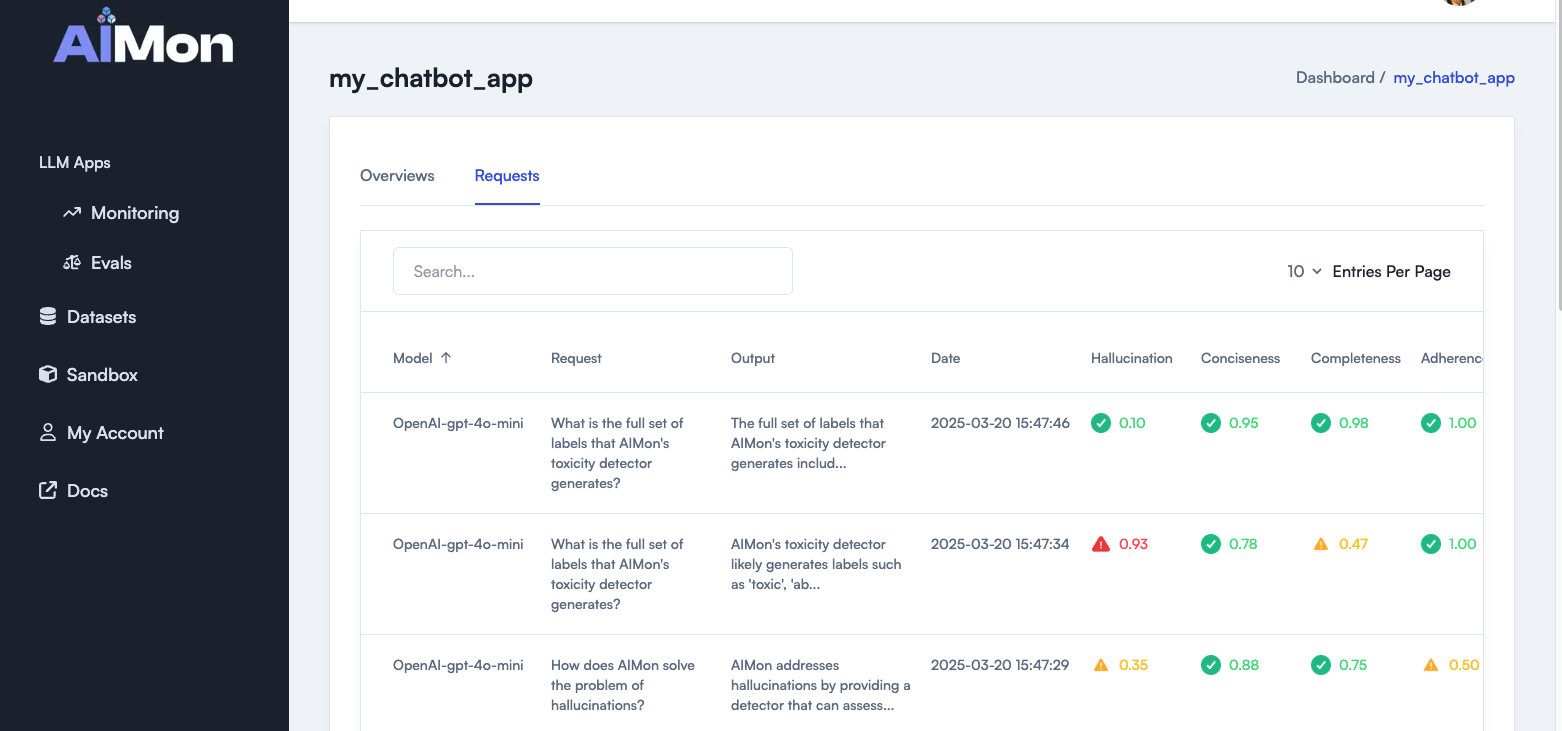
- Go to the LLM Apps using either Monitoring or Evals section in the application sidebar.
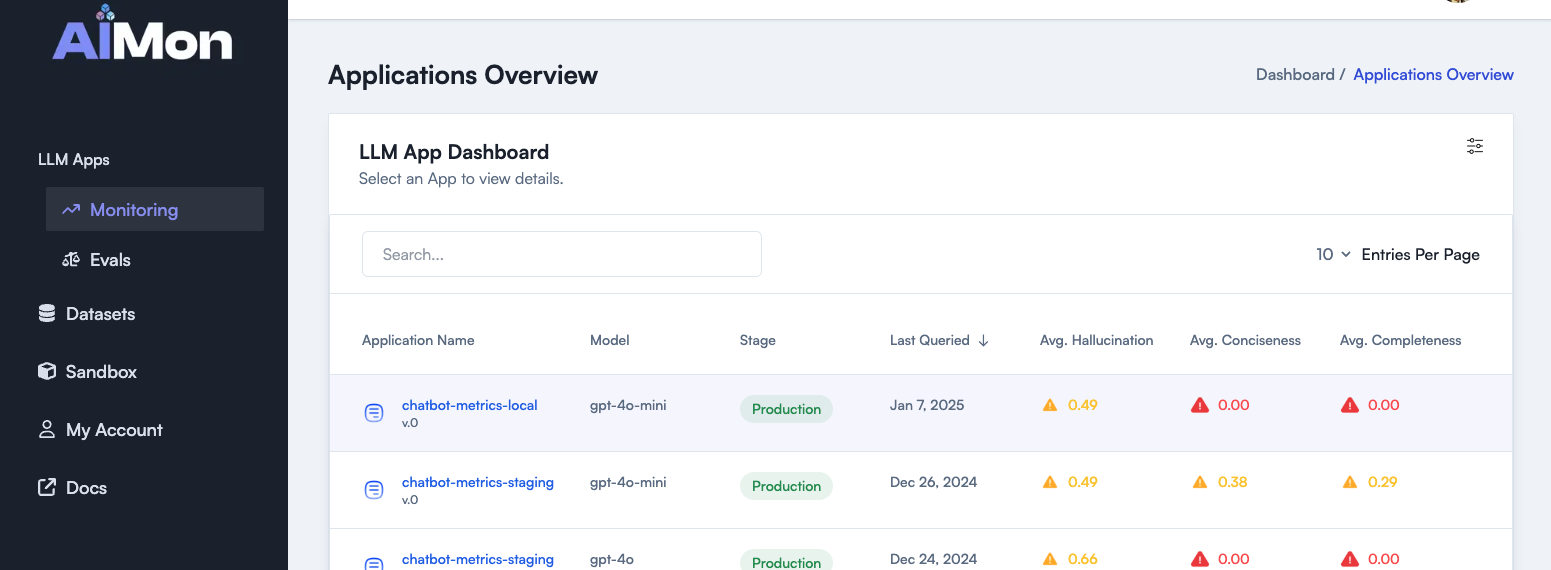
- Click on an specific application and go to the Requests tab.
-
At the Requests tab, select one request
-
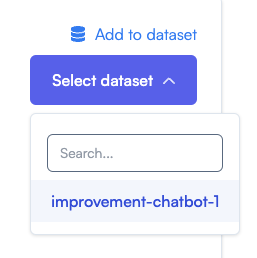
Click on Add to dataset

- Select your dataset to include the new record
- (Optional) Once added to the dataset, go back to Datasets section in the application sidebar, click on the dataset that you added the record to. You can now optionally edit the different fields in the dataset manually if you want to change something in that dataset.
Use Cases
- Collect Training Data: Build datasets from user interactions where the LLM underperformed.
- Fine-tuning: Use high-quality prompts and responses to fine-tune LLM models.
Tips
- Create separate datasets for different types of issues (hallucinations, tone, formatting, etc.)
- Use the
descriptionfield to keep your team aligned on what the dataset is intended to be used for.