Quick Start
Installing AIMon
1. API key
To use AIMon, you will need an API key. You can get an API key by signing up on app.aimon.ai. It is free and doesn't require a credit card.
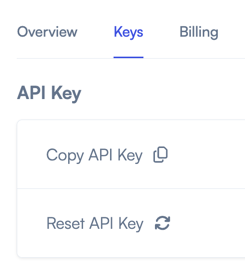
After signing up, find the key by navigating to My Account > Keys on the UI and clicking Copy API Key.
2. Installation
AIMon supports a Python and a TypeScript SDKs which are open-source and can be installed via pip and npm respectively.
- SDK for Python
- SDK for TypeScript
To install the Python SDK, run the following command (Python 3.8+):
pip install -U aimon
3. Run Evaluations or continuously monitor your LLM applications using AIMon
Now you are ready to run evaluations or continuously monitor your LLM applications! In the following example, we use a synchronous decorator created using the Detect function to check for hallucinations.
- Python
- TypeScript
The AIMon Python library provides helpful decorators that reduce the amount of code you need to write to use it. We then use the decorator to annotate the core of your LLM application—the function that talks to your base LLM.
Before running this snippet, set the AIMON_API_KEY environment variable using the API key you got from the AIMon interface in step 1 above.
Refer to the Python API Reference for more information.
from aimon import Detect
import os
# This is a synchronous example
# Use publish=True and async=True to use it asynchronously
detect = Detect(
# These are the values returned by the decorated function in the order they are returned.
# They need to be specified in order to supply the necessary fields for your evaluation.
# Acceptable values are 'generated_text', 'context', 'user_query', 'instructions'. Note that the variable
# names in the decorated function do not need to have the exact same name.
values_returned=['context', 'generated_text'],
config={"hallucination": {"detector_name": "default"}},
# publish=True will publish data to the AIMon UI
publish=True,
api_key=os.getenv("AIMON_API_KEY"),
application_name="my_awesome_llm_app",
model_name="my_awesome_llm_model"
)
@detect
def my_llm_app(context, query):
return context, 'Marie Curie discovered the element Uranium and invented the X-ray machine.'
context, gen_text, aimon_res = my_llm_app(
context="Marie Curie was renowned for her research on radioactivity and was the first woman to win a Nobel Prize, with awards in both Physics and Chemistry.",
query="What are the key achievements of Marie Curie?")
print(aimon_res)
# DetectResult(status=200, detect_response=InferenceDetectResponseItem(result=None, hallucination={'is_hallucinated': 'True', 'score': 0.98432, 'sentences': [{'score': 0.98432, 'text': 'Marie Curie discovered the element Uranium and invented the X-ray machine.'}]}), publish_response=[])
We then use the aimon_client.inference.detect function to call the AIMon API and fetch the evaluation results synchronously.
import Client from "aimon";
// Create the AIMon client. You would need an API Key (that can be retrieved from the UI in your user profile).
const aimon = new Client({ authHeader: "Bearer AIMON_API_KEY" });
const runDetect = async () => {
const generatedText = "your_generated_text";
const context = ["your_context"];
const userQuery = "your_user_query";
// Analyze quality of the generated output using AIMon
const response = await aimon.detect(generatedText, context, userQuery);
console.log("Response from detect:", response);
};
runDetect();
4. Review metrics on the AIMon App UI
As the last step, let's deep dive into the AIMon Application UI. This is where you and your extended team can accomplish the following:
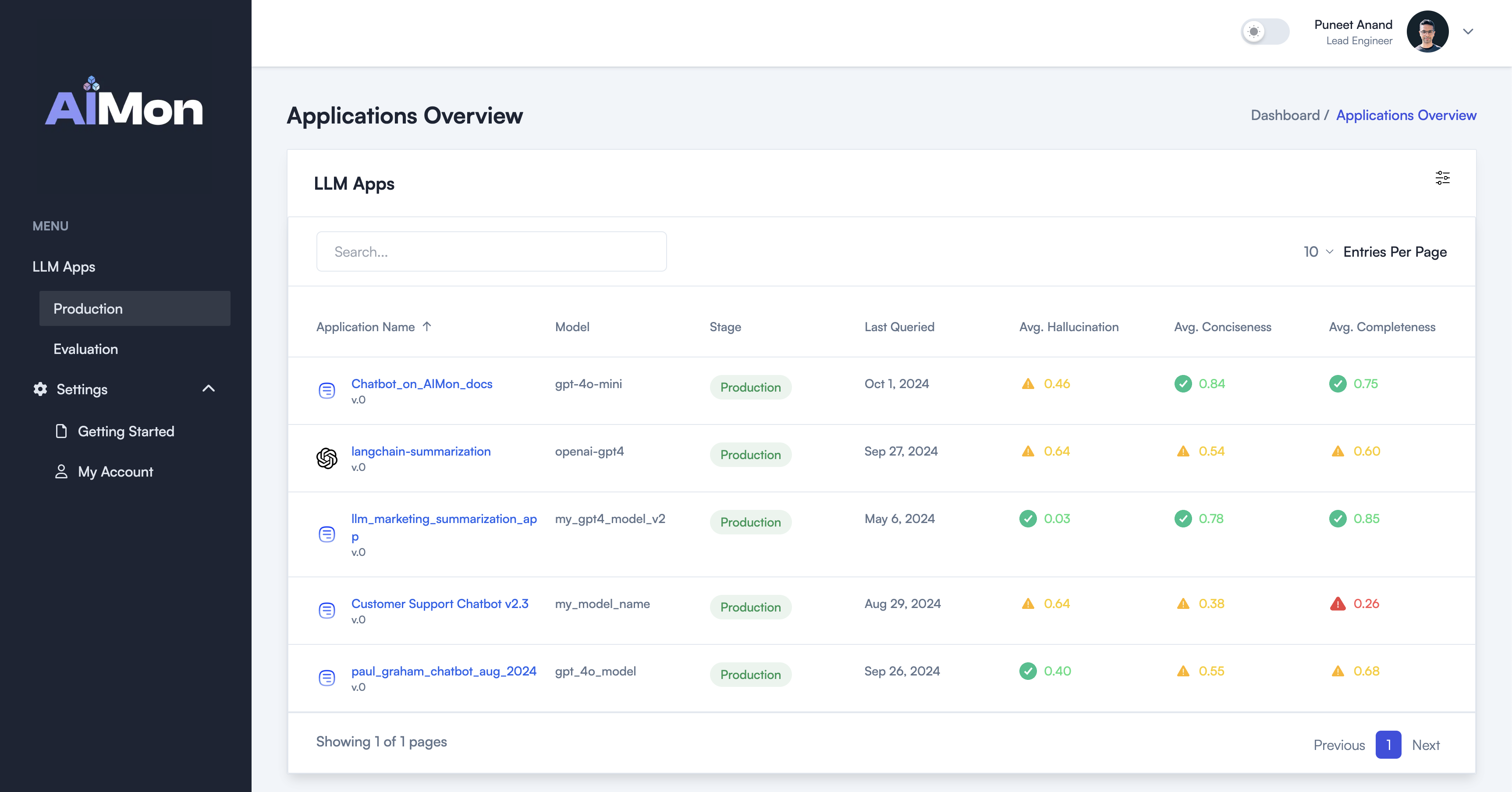
- Discover all LLM apps in your organization with their respective metrics including Hallucination, Instruction Following, Conciseness, and more.
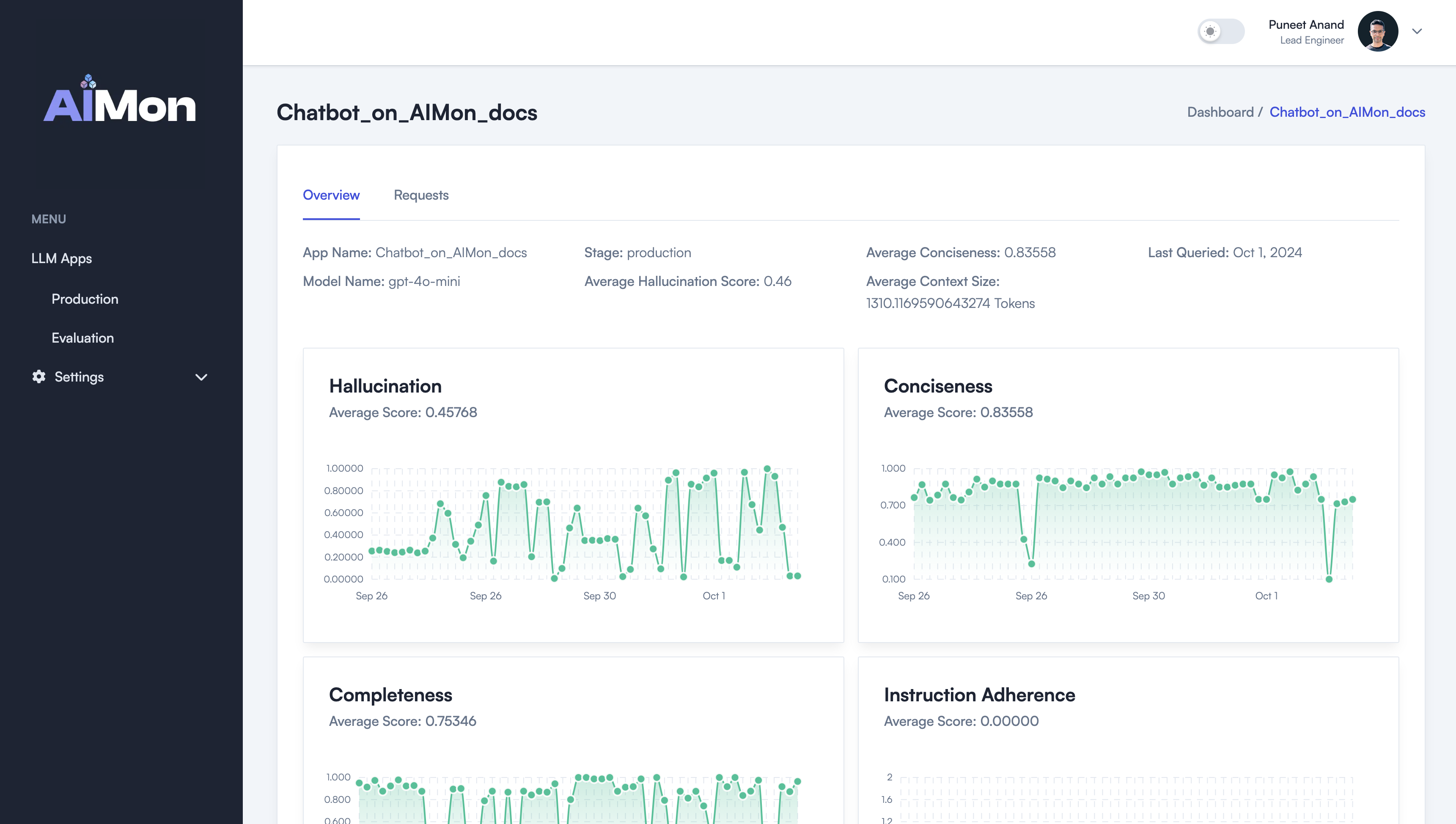
- For each LLM App, review charts and trends of various quality metrics such as Hallucination Rates over time.
- Review quality metrics for any query issued to a production-deployed LLM App.
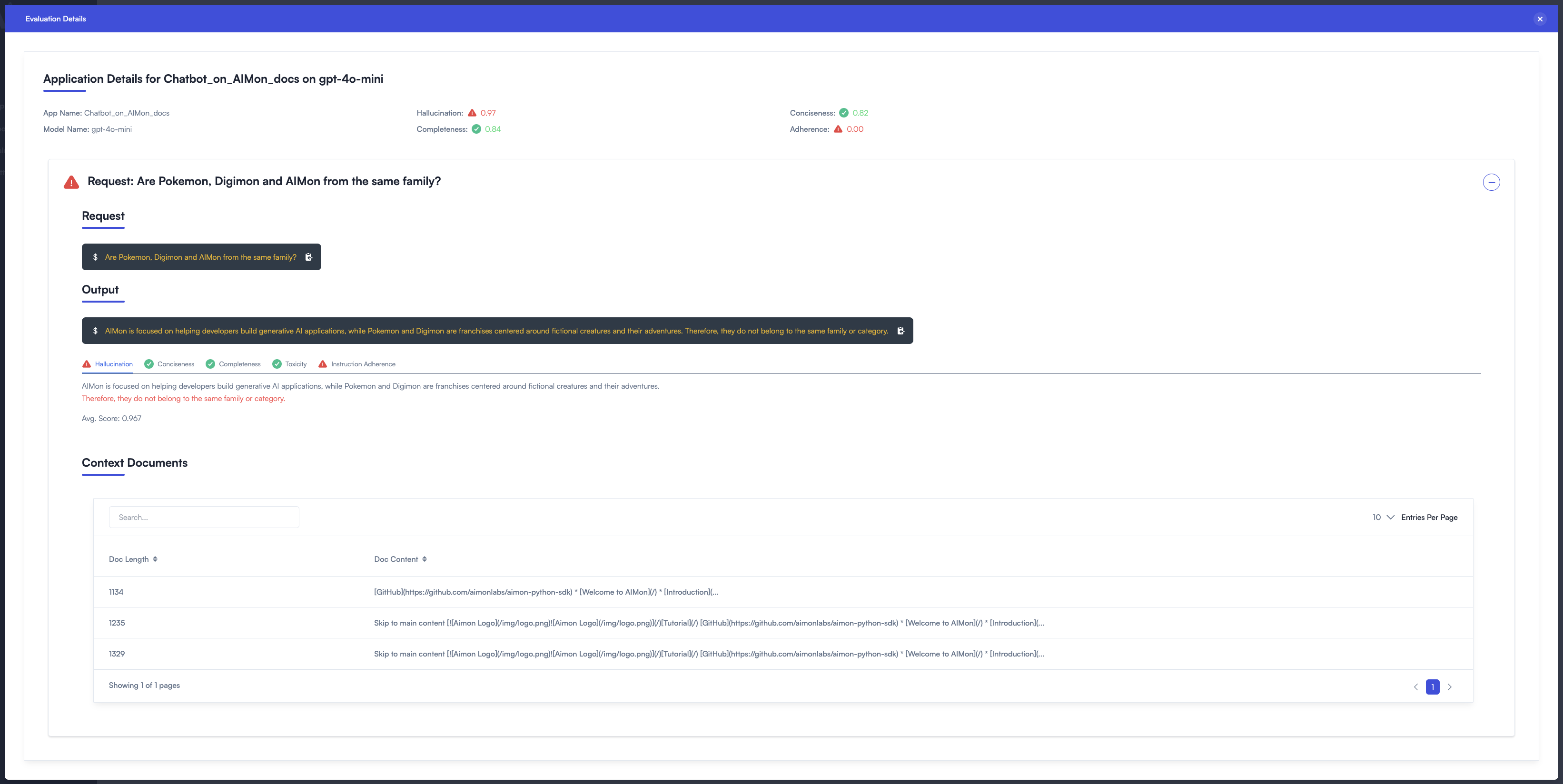
- Trace back each query to the RAG pipeline, understand what data was retrieved and review detected issues with that data.
- Compare evaluations of different LLM apps with different models, versions, datasets, and more.